
О проекте
Проект посвящён исследованию того, как генеративные нейросети могут воспроизводить и интерпретировать художественный стиль Северного Возрождения, в частности визуальный язык, связанный с религиозной драматургией, телесной выразительностью и эмоциональным напряжением. В качестве основы был выбран стиль, вдохновлённый работами Рогир ван дер Вейден, поскольку он ярко передаёт внутренние состояния человека — скорбь, тревогу, покаяние, напряжённое ожидание.

Исходные изображения — картины Рогир ван дер Вейдена
Цель проекта — не просто воспроизвести этот стиль, а исследовать, как нейросеть трансформирует его и создаёт новые визуальные вариации.


Исходные изображения — картины Рогир ван дер Вейдена
Проект поднимает вопрос о том, способна ли нейросеть не только воспроизводить существующий стиль, но и развивать его, создавая новые визуальные образы с сохранением эмоциональной выразительности и глубины.
Концепция серии
Серия изображений представляет собой набор вариаций сцен и образов, объединённых общей эмоциональной атмосферой. Это не копии существующих работ, а новые композиции, в которых сохраняются характерные признаки: — сжатое и замкнутое пространство — выразительные жесты и позы — приглушённая, гармоничная цветовая палитра — ощущение внутреннего напряжения и сосредоточенности Каждое изображение — это вариация состояния человека, переданная через визуальный язык, близкий к живописи Рогир ван дер Вейден.


Результирующие изображения
Исходные изображения (датасет)
Для обучения модели был собран датасет из 100 изображений квадратного формата (1:1), соответствующих требованиям проекта.


Исходные изображения — картины Рогир ван дер Вейдена
Изображения были сгенерированы с помощью базовой модели Stable Diffusion с использованием промптов, ориентированных на эстетику Северного Возрождения. При генерации учитывались следующие параметры: — религиозные или квазирелигиозные сцены — выразительность жестов и телесных поз — мягкая, сбалансированная цветовая гамма — сложная композиция с акцентом на фигурах Отбор изображений производился вручную. В датасет были включены только те изображения, которые: — визуально соответствуют выбранной стилистике — обладают достаточным качеством — демонстрируют разнообразие сцен и состояний Таким образом, датасет представляет собой согласованную, но вариативную выборку, позволяющую модели обучиться ключевым особенностям визуального языка.
Процесс обучения
Обучение генеративной модели проводилось на основе Stable Diffusion с использованием дообучения LoRA.
Основные этапы:
Подготовка датасета — приведение изображений к квадратному формату — проверка качества и стилистической согласованности
Настройка обучения — указание директории с изображениями — задание параметров обучения (batch size, learning rate, количество шагов)
Обучение модели — модель обучалась на выделенном наборе изображений — в процессе обучения формировалось представление о стиле
Генерация изображений — после обучения модель использовалась для создания новой серии изображений — применялись текстовые промпты для управления результатом
В ходе эксперимента было выявлено, что даже при относительно небольшом датасете модель способна уловить ключевые стилистические особенности.
Анализ готовой серии
Итоговая серия изображений демонстрирует, как нейросеть интерпретирует заданный стиль и создаёт новые визуальные решения.
Что удалось передать
— характерная композиционная плотность — эмоциональная выразительность фигур — деформация пространства — акцент на жесте и позе


Результирующие изображения
Вариативность изображений
Несмотря на единый стиль, изображения отличаются: — композицией — количеством персонажей — степенью детализации — уровнем искажения форм Это показывает, что модель не просто копирует, а варьирует визуальный язык.


Результирующие изображения


Результирующие изображения
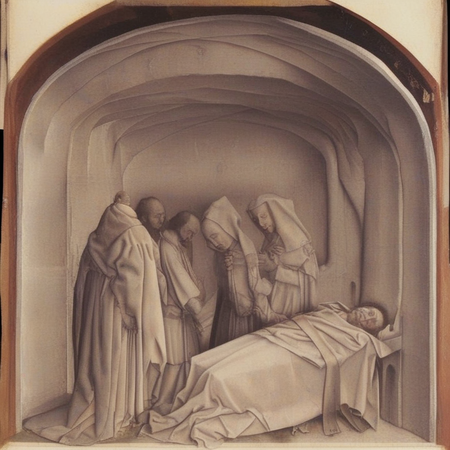

Результирующие изображения
Связь с концепцией
Серия визуализирует идею внутреннего состояния через генеративные изображения. Каждое изображение можно рассматривать как отдельную сцену переживания, объединённую общей эстетикой напряжения и сосредоточенности.
Результирующие изображения
Особенности генерации
— модель может искажать анатомию и пропорции — архитектура иногда становится нелогичной — отдельные элементы усиливаются (жесты, драпировки, позы) — результат зависит от точности и формулировки промпта Таким образом, генеративная модель выступает не только как инструмент воспроизведения, но и как соавтор.
Описание ноутбука
Ноутбук содержит полный процесс обучения модели:
— загрузка и подготовка датасета — создание директории для изображений — настройка параметров обучения — запуск процесса обучения — генерация изображений
Ноутбук демонстрирует практическое применение генеративных моделей для задач стилизации изображений.



